Klassifizierung in der Automotive Data Science – Alles, was ihr wissen müsst
Daten, Daten, Daten – ohne sie geht nichts, aber wie so oft, gilt es auch mit ihnen zunächst zu bestimmen, wie ein (wie auch immer gearteter) Gewinnzuwachs aussehen kann. Interpretierbarkeit ist ein essenzieller Bestandteil, und im industriellen Machine Learning, in dem verschiedenste Modelle mit Daten trainiert werden wollen, gilt dies besonders. In welcher Form liegen die gesammelten Daten vor, und wie geht es weiter? Mit diesen Fragen befasst sich der zweite Teile unserer Artikelreihe über industrielles Machine Learning mit dem heutigen Thema der Klassifizierung. Den ersten Artikel zum Thema Clustering findet ihr hier ► klick den Link und grüß Captain k-means von uns!
An dieser Stelle nun fahren wir fort mit der Erklärung zur Klassifizierung, für die wir uns unter anderem Input unseres Team Lead Data Science & A.I., Dr. Daniel Isemann, eingeholt haben – viel Spaß!
- Was ist Klassifizierung, und bitte nicht nur graue Theorie, sondern Beispiele!
- Klassifizierung – Funktional und effizient, aber auch ein bisschen lustig
- Wie verorten wir Klassifizierung im Bereich des Machine Learning?
- Klassifizierung und ihre Verfahren: Die wichtigsten Algorithmen
- Klassifizierung und Labels: Wie viele Leute muss ich da denn jetzt dransetzen?
- Klassifizierung und das Bauchgefühl – Partners in Crime?
- Abschied von der Klassifizierung (…aber doch nur für heute!)

Marc
Marketing Professional
14.11.22
Ca. 16 min
Was ist Klassifizierung, und bitte nicht nur graue Theorie, sondern Beispiele!
Räumen wir zunächst eine rein sprachliche Kleinigkeit aus dem Weg: „Klassifizierung“ kann auch „Klassifikation“ genannt werden, und du darfst sowohl „klassifizieren“ als auch, etwas weniger bekannt, „klassieren“ sagen. Interessanterweise ist das aus dem Sport geläufige „er wurde deklassiert“ etwas bekannter, obgleich sprachlich eigentlich meist ungenau benutzt. Zurück zum Bereich des Machine Learning begegnet euch aufgrund der hohen Anzahl an Anglizismen auch oft die englische „classification“. Indes, sie alle beschreiben das gleiche, nämlich eine Methodik zur Einteilung von (Daten-)Objekten in Klassen.
Im industriellen Machine Learning – in diesem Artikel nicht ausschließlich, aber bevorzugt auf den Automobil-Sektor bezogen – reden wir von jeder Menge Daten. Petabyte von auf den Straßen gesammelten Daten, via Testfahrzeugen, Videostreams, gewaltigen Bildmengen und weiteren Quellen, die in kurzer Zeit gigantische Datenberge anhäufen. Um das Abstrakte – das hier eine große Rolle spielt – etwas deutlicher zu machen, verwenden wir ein Beispiel: In einem Fahrzeug mit autonomen Fahrassistenzsystemen gibt es einen Elektromotor, der sich aber nur einschaltet, wenn eine Kamera ein Signal an das betreffende Steuergerät leitet. Dies macht die Kamera bzw. die dahinterliegende K.I., wenn sie eine rote Ampel erkennt – der Elektromotor schaltet sich ein, der Benzinmotor sich aus, und das Fahrzeug gleitet elektrisch bis zum Stillstand oder dem Weiterfahren und senkt somit den Benzinverbrauch. Die Kamera muss also zunächst die Ampel automatisch erkennen, und danach die Stellung der Ampel, die sich aus Farbe und Position zusammensetzt. Woher weiß die K.I. nun also, was „richtig“ und was „falsch“ ist? Wie trifft sie diese Entscheidung, die für uns Menschen eigentlich recht einfach ist? Es wurde ihr antrainiert, mittels eines Modells, in dem bestimmt wird, was grün (fahren, Elektromotor nicht einschalten) und rot (in den „Segelmodus“ umschalten und via Elektromotor bis zur Ampel gleiten) ist. Dieses Modell wurde mit Daten gefüttert, mit Bildern, Videos und Signalen von roten und grünen Ampeln, im Stillstand, in Bewegung, aus verschiedensten Winkeln, möglicherweise berücksichtigend, ob sich Objekte zwischen Ampel und Fahrzeug befinden, andere Verkehrsteilnehmer beispielsweise. Kategorisiert und somit ausgewertet und in sinnvolle Signale verarbeitet wurden diese Daten mittels Klassifizierung.

Klassifizierung – Funktional und effizient, aber auch ein bisschen lustig
Damit diese gesammelten Daten verwertbar werden und nicht nur ein unbestimmtes Signal in einem mehrdimensionalen Raum sind, benötigen sie ein Label, und zwar „grün“ oder „rot“ in unserem Beispiel. Dies kann auf verschiedene Weisen unternommen werden: Natürlich manuell, indem eine Testperson klar definiert, ob ein z.B. Bild eben eine rote oder grüne Ampel zeigt. Eventuell einigen sich mehrere Personen, wann genau eine Ampel rot oder grün ist – oder gegebenenfalls gelb. Eine beliebte Form manuellen Labelns stellen spezifische Online-Foren dar, in denen viele User in vergleichsweise kurzer Zeit viele Daten zuordnen können. Bei sehr großen Datenmengen bietet sich indes eine Automatisierung per Algorithmus an – aufgrund der fehlenden Label kann die Klassifizierung hier noch nicht greifen, aber Clustering könnte eine Lösung sein, ob nun bereits als finales Verfahren, mit dessen Ergebnissen ein Modell bereits ausreichend trainiert werden kann, oder ob als Vorstufe zur Klassifikation.
Haben wir nun also die gelabelten Daten vorliegen, können wir das Modell trainieren, und dieses kann neu hinzugefügte Daten, die zuvor nicht unbekannt waren, finden und kategorisieren, sprich: klassifizieren. Ein anderes beliebtes Beispiel ist der uns allen bekannte Spam-Filter des E-Mail-Postfachs: Ist die eingehende E-Mail Spam oder nicht? Hier gibt es fast schon amüsante Beispiele für die Logik, die dieser spezifischen Form der Data Science innewohnt: Wir versenden 100 E-Mails, eine davon ist Spam. Der Spamfilter erkennt diese Spam-Mail nicht, sondern stellt alle Mails problemlos zu – so ist er zunächst dennoch zu 99 Prozent akkurat. Um dies abzumildern, sind entsprechend hohe Datenmengen nötig, was wiederum manuelles Labeln ad absurdum führt und in der Folge verlässliche Algorithmen benötigt, die ein gutes Modell entwickeln und später auch weiter upgraden können.
Es versteht sich in diesem Zuge auch, dass die Daten verlässlich und präzise sein müssen, damit ein Modell zuverlässig arbeiten kann. Ein fehlerhaftes Labeln würde konsequenterweise auch zu einem fehlerhaften Modell führen. Spätestens in häufiger Ausgabe von „false negatives“ oder „false positives“ (also dem Nichtabschalten des Motors trotz roter Ampel, oder ständigem Spam im Postfach) würden Fehler im Modell zutage treten. Eine gute Klassifizierung und ein in der Folge starkes Modell kann diesem unerwünschten Fall aber gut vorbeugen.
Wie verorten wir Klassifizierung im Bereich des Machine Learning?
Sprechen wir vom „Machine Learning“, beziehen wir uns üblicherweise auf die Definition von Arthur L. Samuels: “Programming computers to learn from experience should eventually eliminate the need for much of this detailed programming effort.“ Es geht also ums Lernen – Samuels beispielsweise programmierte schon 1959 eine Dame-spielende Anwendung, die den Landesmeister Connecticuts im Damespielen besiegte, obwohl Samuels selbst nicht besonders gut darin war (nachzulesen im Buch „Computers and Thought“ von Edward Feigenbaum und Julian Feldman). Die gerne genutzte Floskel, dass ein Programm nur so gut sei wie dessen Programmierer, lässt sich dank Machine Learnings also einfach widerlegen. Bedeutet also insgesamt, dass Machine Learning sich darauf bezieht, Lernvorgänge zu vereinfachen. Freilich hat sich dies bis in die heutige Zeit weiterentwickelt und sich zu Industrie-Lösungen hochskaliert und kommt in einer Vielzahl von Szenarios im Alltag zum Einsatz, ob im Finanzsektor, in der Medizin (hier empfehlen wir euch unseren richtig spannenden Artikel, in dem wir erklären, wie im Automotive-Sektor gewonnene Data-Science-Erfahrungen die Medizin erobern) oder eben in der Automobilbranche. Oft geht es, wenn dort die Rede vom industriellen Machine Learning ist, meist um Neuronale Netze oder Deep Learning.
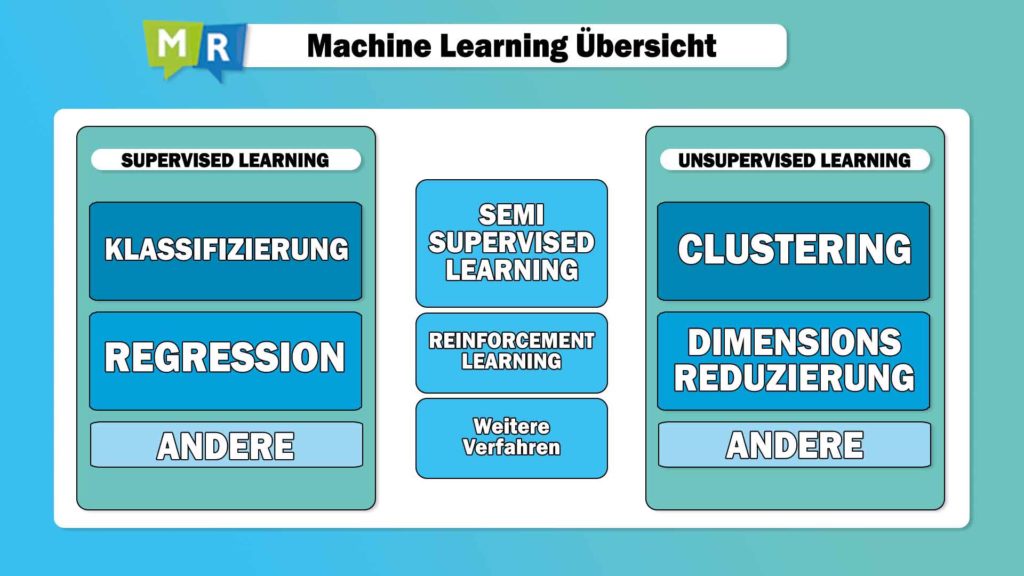
Innerhalb dieses Bereichs unterscheiden wir hauptsächlich zwischen den überwachten und den unüberwachten Lernverfahren. Im unüberwachten Bereich können wir eine erneute Einteilung in entweder Clusteringmethoden vornehmen, oder in Verfahren zur Dimensionsreduzierung – die erklären wir euch in einem separaten Artikel, sonst wird es ein bisschen zu detailliert für heute.
Demgegenüber steht der Bereich des Supervised Learning, also der überwachten Lernverfahren, von denen die Klassifizierung sicherlich den prominentesten Vertreter stellt. Ehrennennungen gehen an die Regressionsanalyse, bei der keine Klassen, sondern numerische Werte vorhergesagt werden sollen – ein völlig anderes Anwendungsszenario also als bei der Klassifizierung, bei der Klassen vorhergesagt werden, also beispielsweise „A“, „B“ oder „C“ (oder ein Bucket, bei dem alles von „0-1“ zu „A“ gehört, alles von „1-20“ zu „B“ usw.). Es geht in der Klassifizierung also um Kategorien, um Label, mit denen das gewünschte Modell trainiert wird, das am gesendeten Kamerabild also schließlich erkennen kann, dass unser Steuergerät für den Elektromotor aktiviert werden soll.
Klassifizierung und ihre Verfahren: Die wichtigsten Algorithmen
Innerhalb der Klassifikation blicken wir auf eine weitere Reihe von Verfahren, die sich für die Klassifizierung der Daten anbieten, und über die wir gleich noch im Genaueren sprechen, aber erstmal allgemein gesprochen: Einen großen Teil der bekannten Anwendungen bilden die Neuronalen Netze (die sich theoretisch auch für alle anderen Verfahren anwenden ließen, insbesondere beim Reinforcement Learning), und ähnlich bekannt und häufig eingesetzt sind die kernelbasierten Verfahren (Support Vector Machines).
Zum zuvor noch nicht genannten „Reinforcement Learning“ sei an dieser Stelle überaus zusammenfassend gesagt, dass es sich dabei ähnlich zu anderen Verfahren aus dem „Semi-Supervised Learning“ um ein Lernparadigma handelt, das weder überwacht noch unüberwacht ist – auch hierauf gehen wir noch in einem kommenden Artikel weiter ein.
Ebenfalls von hoher Relevanz in der Klassifizierung sind die baumbasierten Verfahren wie die schon seit längerem bekannten Decision Trees – wenngleich diese inzwischen eher in Ensembles genutzt werden, ganzen Tree-Feldern oder Forest-Methoden (bekanntester Vertreter sicherlich „Random Forest“). Wer nicht viele Daten hat, aber schnelle Ergebnisse braucht, greift auch gerne auf „Extreme Gradient Boosting“ zurück, gemeinhin eher als „XG Boost“ betitelt.
Die Frage, welcher Algorithmus in der Klassifizierung der große Gewinner ist, bleibt indes schwierig zu beantworten. Oft ist es jener, mit dem der entsprechende Dienstleister die größte Erfahrung hat, und noch häufiger werden die Daten einfach mit mehreren Algorithmen bearbeitet. Im Ergebnis-Vergleich zeigt sich, welcher Algorithmus am besten geeignet ist. Dieser wird entsprechend eingesetzt, um das finale Modell zu trainieren. Letztlich ist es oft auch eine Frage des Budgets – wer viele Daten hat und sich leisten kann, ein Modell ausführlich zu trainieren, kann mit Deep Learning arbeiten, das sich hier auch gerne als stärkster Teilnehmer im Feld der Klassifizierungs-Algorithmen präsentiert. Liegen jedoch nur wenige Daten vor, ist auch Deep Learning nicht besser als andere Algorithmen, und mehr als einmal zeigte sich XG Boost am Ende des Tages als Gewinner.

Klar ist auch – je mehr Daten vorliegen, desto genauer wird ein Ergebnis in aller Regel, was indes auch zu Lasten der Interpretierbarkeit geht, und die Erfahrung bringt die Erkenntnis mit sich, dass sich die meisten Algorithmen am Ende doch ähnliche Ergebnisse liefern – ausgenommen hier erneut Muskelprotz „Deep Learning“, womit sich die exaktesten Ergebnisse vor allem im Langzeitverlauf ermitteln lassen.
Klassifizierung und Labels: Wie viele Leute muss ich da denn jetzt dransetzen?
Diese Daten müssen nicht nur gesammelt, sondern, wir sprachen bereits darüber, auch gelabelt werden, da Supervised Learning nun mal auf Labels angewiesen ist. Hier gibt es durchaus unterschiedliche Wege, an diese Labels zu gelangen, obwohl in vielen Köpfen noch die Vorstellung besteht, man benötige eine große Menge an Personen, die einen hohen Aufwand betreiben, um Daten manuell zu labeln – was Zeit und Ressourcen benötigt und Kosten erzeugt. In der Realität können Label aber bisweilen auch ohnehin ablaufenden Prozessen erzeugt werden, wie beispielsweise der Bewertung von Fehlertickets durch Fachexperten im Rahmen des Problem-Managements oder durch User-Feedback und ähnliche Quellen. Hieraus lassen sich oft direkt oder indirekt Label ableiten, die für die eigentliche Klassifikationsaufgabe verwendet werden können.
Indes ändert dies nicht den Umstand, dass Daten auch interpretierbar sein sollten, gegenüber der Modellgüte. Zum besseren Verständnis: Nutzen wir einen Decision Tree, so lässt sich an jeder Abzweigung nachvollziehen, wieso die entsprechende Entscheidung gefallen ist, wir können also das ausschlaggebende Entscheidungskriterium verstehen. Wieso ein bestimmter Datenpunkt in eine spezifische Klasse kategorisiert wird, ist mehr oder minder eindeutig.
Am anderen Ende des Spektrums steht beispielsweise ein Verfahren wie Deep Learning. Hier bestehen hunderte, tausende oder mehr „Datenknoten“ in einem hochkomplexen Modell, deren Interpretierbarkeit nicht mehr gegeben ist. Hier ist fast schon hinzunehmen, dass die Entscheidung eben aufgrund der vorgegebenen Trainingsdaten getroffen wird, ohne im Detail einzusehen, wie es zur Entscheidung kam.
Klassifizierung und das Bauchgefühl – Partners in Crime?
Nicht unbedingt fachlich belastbar, aber dennoch ein schönes Beispiel ist das eines Automechanikers: Diese kann anhand bestimmter Regeln bestimmen, ob ein Motor zu laut ist, was auf einen spezifischen Schaden schließen lässt. Überprüft man dies nun, lässt sich der Fehler finden, und beheben. Das ist einfach und nachvollziehbar. Es gibt indes aber auch Schäden, die ähnlich klingen, aber andere Ursachen haben. Diese zu finden, erfordern möglicherweise auch neue Erkennungsmuster. Ein erfahrender KFZ-Meister nun wiederum „kennt“ den Motortypen indes sehr genau und kann aufgrund „Bauchgefühls“ eine durchaus kompetente Entscheidung treffen. Dies ist kein transparenter Prozess und eher schwierig zu kommunizieren und nachzuvollziehen, somit auch nicht konkret in gleicher Form wiederholbar. Dennoch ist dieses Beispiel durchaus naheliegend, da vor allem Neuronale Netze durchaus eine gewisse Nachbildung menschlicher Entscheidungsfindung darstellen sollen, und somit auch Intuition eine Rolle bei der Klassifizierung spielt – vereinfacht erklärt.
Sich entscheiden zu müssen zwischen Interpretierbarkeit und Modellgüte ist nicht immer einfach; indes, wie so oft gibt es durchaus verlässliche Mittelwege, von denen hier Random Forest besonders zu nennen ist: Hier ist zwar keine Erklärbarkeit an jeder einzelnen Abzweigung in der Entscheidungsfindung mehr möglich, aber Einblick in die übergreifenden Entscheidungskriterien besteht durchaus.
Abschied von der Klassifizierung (…aber doch nur für heute!)
Beginnen wir das Fazit des Beitrags mit einem Zitat, das Daniel Keys Moran zugeschrieben wird, einem Programmierer und Autoren: „Du kannst Daten ohne Informationen haben, aber keine Informationen ohne Daten“. Im Rahmen des industriellen Maschine Learnings ist es in der Regel die dritte Variante, nämlich: Viele Daten mit vielen Informationen, die es zu sortieren, sprich: klassifizieren gilt, um eine Auswertung überhaupt erst zu ermöglichen und somit den Betrieb vieler Funktionen und Produkte. Insbesondere bei extrem hohen Datenmengen ist eine effiziente Nutzung der gesammelten Informationen ohne Big Data Pipelines, Machine Learning und Clustering oder Klassifizierung kaum möglich. Wir beraten natürlich gerne, wenn zu viele Daten Fragen aufwerfen oder anderweitig effizient ausgewertet werden sollen. Und empfehlen euch, sich noch weiter auf unserem Blog umzusehen, sei es zum Thema Data Science oder unseren anderen spannenden Portfolio-Themen.







