Von K.I. bis zum LLM – Endlich die Rocket Science dahinter verstehen
Eine Hilfestellung für alle, die mitreden möchten!
Warum braucht es einen weiteren Artikel, der etwas Licht auf die Technik wirft, die uns aktuell und in Zukunft noch viel mehr beeinflussen wird?
Glaubt man dem aktuellen LinkedIn-Kanon, scheint doch alles in Sachen A.I. vollkommen selbsterklärend zu sein. Jeder ist seit neustem ein A.I.-Experte, nutzt aufgeregt die angesagten Tools dazu, implementiert fleißig vordefinierte Bausteine in die Company IT-Architektur hinein und sieht A.I. als etwas, ohne das wir vorher nie leben konnten, oder? Ihr seht schon, dieser Artikel wird hier und da auch ein wenig mit Zynismus um sich werfen😉
Innerhalb nur eines Jahres entwickelten sich neue, schicke Influencer-Zweige, welche hyperaktiv den Einsatz von A.I. in allen Branchen von Alpha bis Omega „diskutieren“. Selbsternannte A.I.-Experten, die sich auf den vielen neuen „Selfie-Tech-Events“ positionieren und hoffen, auf den nächsten Deep Talk eingeladen zu werden.
Bin ich damit nun der einzige Ex-Informatiker, der die fachlichen Hintergründe von selbstlernenden Systemen durchaus komplex findet? Sich ernsthaft versucht, die Mechanismen jenseits der Youtube-Erklärvideos vorzustellen, um ein Gefühl davon zu bekommen, was eigentlich „Intelligenz“ bedeutet?
Was macht denn Intelligenz im Kern aus, was bedeutet schöpferische Entscheidung in diesem Kontext und lässt sich das in einem neuronalen Netz an irgendeiner Stelle heute bereits finden? Brauchen wir dazu vielleicht erst den „wahren“ Zufall auf Quanten-Computing Ebene? Wie spielen überwachtes und unüberwachtes Lernen mit LLMs zusammen? Fragen, die sich automatisch auftun, wenn man sich in diese Thematik eindenkt. Fragen, deren Antworten entscheidend bei der Einordnung von A.I. helfen und auch die damit verbundenen Ängste neu ordnen können. Antworten, die aber nicht nur entmystifizieren, sondern zugleich den Entwicklern, die sich im Kern mit dieser hochkomplexen Entwicklung beschäftigen (und nicht nur Module kombinieren), die Aufmerksamkeit zukommen lässt, die sie meiner Meinung nach verdient haben – und das meist so ganz ohne Selfie.
Aber nun gut, gehen wir es an. Blicken wir Schritt für Schritt tiefer hinein in die Magie von LLMs.
- Supervised Learning- hier sollten wir starten
- Der erste Schritt (noch recht einfach zu erklären): Feature Engineering
- Supervised Learning und der Mensch im System.
- Warum macht das neuronale Netz das? Wer sagt dem Netz, dass es sich verändern soll?
- Wo passiert nun „Magie“? Oder doch noch nicht?
- Unsupervised Learning oder unüberwachtes Lernen: Gehen wir einen Schritt weiter!
- Gigantisch große Sprachmodelle, LLMs, Generative A.I. und der letzte große Schritt!
- Über multidimensionale Vektorräume, die gute, alte Mustererkennung und neuronale Netze.
- LLMs: Und was hat es nun mit dem Vektorraum auf sich?
- LLMs: Und was ist mit der Belohnung?
- Wie generiert das LLM die Antwort?
- Lessons learned: Die Magie steckt zwischen den Zeilen, nicht im schöpferischen „Neuen“

Michael
Marketing Professional
15.12.23
Ca. 25 min
Supervised Learning- hier sollten wir starten
„Supervised Learning“, oder „Überwachtes Lernen“ – Warum starten wir hier und nicht bei kleineren Sprachmodellen oder noch näher verwandten Gebieten? Weil ich finde, dass hier ein paar Aspekte entscheidend zum Verständnis beitragen können.
Man hat sicher schon einmal die Aufgabenstellung oder Beispiele für Supervised Learning gesehen. Meist waren dies Bilder, in denen beliebige Dinge markiert wurden und mit einem Label der Art „Das ist ein Auto“, „Pflanze“, „Straßenschild“ oder Ähnlichem versehen waren.

Eines der naheliegendsten Anwendungsgebiete ist nun mal das Erkennen von Objekten in einem sonst vollkommen unstrukturierten Bild. Für uns Menschen eine triviale Aufgabe, denn wir haben über unser Leben hinweg gelernt, anhand von bestimmten Mustern wie Formen, Farben, Kantenverläufen, Schattierungen und Kontext zu anderen Dingen Objekte innerhalb von Millisekunden erkennen und einordnen zu können. Gibt man einen abstrakten Pixelbrei – denn nichts anderes ist ein Bild – einem klassischen Algorithmus der Informatik, dann ist das eine sehr schwere Aufgabe. Oder mit den Worten eines berühmten Filmzitats: „Nein das ist keine schwierige Aufgabe, Mr. Hunt, das ist eine unmögliche Aufgabe!“
Der erste Schritt (noch recht einfach zu erklären): Feature Engineering
An irgendeiner Stelle muss man beginnen, einem Computer bzw. einem Stück Software beizubringen, wonach es suchen muss. Ohne geht es schlicht nicht. Also besteht der erste Schritt im Supervised Learning darin, vorzugeben, mit einer vorab definierten und durchaus bekannten Menge an Filtern nach bestimmten Mustern im Bild zu suchen. In der Praxis heißt die Aufgabenstellung, dass z.B. nach einem Kreis gesucht wird, einer beliebigen Farbe, einem gut erkennbaren horizontalen oder vertikalen Kontrast, was eine Kante vermuten lässt, oder einer bestimmten Sequenz aus all diesen Ereignissen im Bild. Weil all diese Filter an jeder beliebigen Stelle im Bild angewendet werden können, die Reihenfolge unterschiedlich sein kann, die Filter in ihrer Größe variieren sollten, nicht alle Stellen im Bild gleich wichtig sind und sich auch einige Entscheidungen entlang dieser sehr komplexen Mustererkennung gegenseitig ausschließen, wird klar, dass man dies nicht mit einem klassischen Entscheidungsbaum der Art „Wenn das passiert, dann dieses oder jenes“ („if_then_else“) aus der Informatik abfrühstücken kann. Und schon sind wir bei einem weiteren „magischen Begriff“, dem neuronalen Netz. Im Grunde werden wir hier auch nicht in die Tiefen eintauchen, aber das brauchen wir auch nicht. Vielmehr versuchen wir, uns ein vereinfachtes, aber sehr passendes Bild davon vorzustellen: Ein Netz aus Knoten (Synapsen) und Linien (Kanten zwischen den Synapsen). Jeder Knoten trägt eine bestimmte Entscheidung in sich, jede Kante spricht für die Verbindung und damit das Gewicht zwischen diesen einzelnen Entscheidungen. Entscheidungen in den Knoten können zum Beispiel die schon mehrmals angesprochene Mustererkennung (oder Teil einer solchen) im Bild sein. Vereinfacht gesagt: Man kippt vorne beim ersten Knoten ein Bild hinein und bekommt hinten am Ende des neuronalen Netzes die finale Entscheidung präsentiert, ob dieses oder jenes Objekt ein Hund, Katze, Auto oder sonst etwas ist.
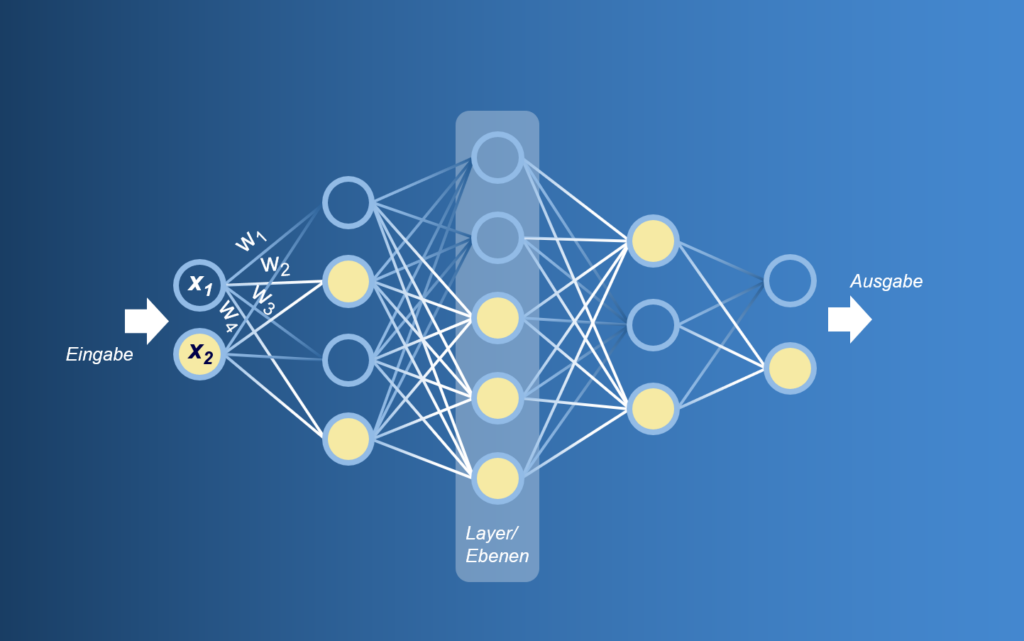
Supervised Learning und der Mensch im System.
Beim überwachten Lernen spielen „gelabelte Daten“ und der Mensch selbst eine wichtige Rolle, indem sie dem neuronalen Netz einen Anreiz liefern, etwas zu lernen oder besser gesagt, um die Entscheidungen immer besser treffen zu können. Das Netz ist nämlich in der Lage, die Knoten und Kanten beliebig zu gewichten. Diese Gewichtung entspricht beispielsweise der Logik, dass dieses oder jenes Feature (erkannte Eigenschaft im Bild, die mit einem zur Verfügung stehenden Filter erkennbar wird) wichtiger ist als ein anderes. Ähnlich einem Wasserstrom, der von vorne bis hinten durchläuft, wird somit der Entscheidungsweg „umgeleitet“. Stellt sich ein Weg als nicht sinnvoll heraus, kann über die Gewichtung ein Knoten auch jederzeit eingeschränkt werden: Der Wasserstrom also entlang eines anderen Weges geschickt werden.
Am Ende steht der Mensch, denn es wird beim supervised Learning von Hand entschieden, ob die vom neuronalen Netz gefunden Objekte mit den zuvor markierten Objekten übereinstimmen.
Warum macht das neuronale Netz das? Wer sagt dem Netz, dass es sich verändern soll?
Warum macht das Netz nun all dies? Ganz einfach, weil die Rahmenbedingungen so vordefiniert wurden, dass es durch die Veränderung der Werte in den Knoten und Kanten immer genauer das zu erkennen versucht, was in den gelabelten Daten erkannt werden soll. Die richtige Lösung nennt sich Ground Truth und ist genau dann erreicht, wenn eben in einem Bild (natürlich ohne Kästchen um den Hund) genau an der Stelle der Hund erkannt wurde, wo er sein soll. Ist dies nicht geglückt, wird dem Netz ein Feedback gesendet, dass dies nicht die richtige Lösung war und es eine andere Gewichtung der Knoten und Kanten versuchen, oder gar neue Muster mit den verfügbaren Filtern finden soll.
Wo passiert nun „Magie“? Oder doch noch nicht?
Zunächst sollten diese Ausführungen zu einer ersten Entmystifizierung führen, denn das neuronale Netz als große Schleuse für viele Wasserströme klingt erstmal nicht nach einer die Weltherrschaft an sich reißenden Supermacht. Blicken wir etwas tiefer hinein, finden wir jedoch schon an einer Stelle etwas Verblüffendes: Das neuronale Netz verfügt über eine „kleine Superpower“ die sich „Convolution“ nennt. Und das ist genau jener Mechanismus, der selbstständig und ohne explizites Zutun von außen neue Filter einbaut und prüft. Es lernt – oder es sieht zumindest in Ansätzen aus, wie das, was wir als „menschenähnliches lernen“ bezeichnen könnten. Und das ist durchaus erstaunlich und auch stellenweise kontraintuitiv.
Der Anreiz, dies zu tun, begründet sich hingegen lediglich daraus, immer bessere Entscheidungen bei der Objekterkennung zu treffen. Also keine intrinsische Motivation, auch wenn es zunächst danach aussieht. Auch die im Netz verwendbaren Filter sind vordefiniert und in ihrer Art und Wirkung begrenzt. Sie werden lediglich durchprobiert, neu kombiniert und dann im Netz, je nach Qualität des Endergebnisses, fixiert. Faszinierend, aber echte, gar schöpferische Gestaltung neuer Filter findet nicht statt. Es lässt sich vermuten, dass diese Schöpfung eine Art „Zufall“ voraussetzt, von der wir im IT-technischen Kontext wissen, dass wir selbst mit den aktuellen Zufallsgeneratoren der IT dem aus der Physik und dem Alltag bekannten Zufall nicht nahe kommen. Mag sein, dass sich vorerst dieser Herausforderung kaum entgegentreten lässt.
Die schiere Komplexität und Größe des neuronalen Netzes sind in der Praxis jedoch so überwältigend und zugleich die Leistungsfähigkeit so hoch, dass es selbst Experten immer wieder den Atem raubt. Selbst die „erlernten“ Entscheidungswege bei kleineren neuronalen Netzen sind von außen betrachtet nicht mehr nachvollziehbar, denn sie wurden eben nicht explizit programmiert, sondern eigenständig konfiguriert. Und das ist dann schon ein wenig Magie.
Unsupervised Learning oder unüberwachtes Lernen: Gehen wir einen Schritt weiter!
Der Unterschied zu den überwachten Verfahren klingt im ersten Moment recht einfach: Man verwendet zum Training des neuronalen Netzes keine Daten (oder in unserem Beispiel Bilder) bei denen klar ist, wie das Ergebnis auszusehen hat, sondern stattdessen Daten, ohne jegliche „Hilfestellung“. Nochmal vereinfacht formuliert: Man möchte erreichen, dass vorne in das neuronale Netz beliebiger Input an Bildern oder Videostreams eingeleitet werden kann und am Ende das Netz diesen Input „irgendwie“ für sich strukturiert bzw. dieser geclustert wird, um dann in einem weiteren Schritt etwas Bestimmtes ableiten zu können. In der Praxis möchte man zum Beispiel erkennen, welche Bilder zueinander ähnlich wirken, auf welchen Bildern Auffälligkeiten gegenüber den anderen Bildern erkennbar sind oder welche Muster sich in einer beliebigen Text oder Zahlenkolonne verbergen. Dieses „irgendwie“ klingt erst einmal sehr abstrakt und vage – und genauso ist es auch (leider) in der Praxis. Mit diesem „irgendwie“ geben wir nämlich dieses Mal dem neuronalen Netz vorab nicht die Aufgabe, die Features (und damit die Gewichtung der Kanten und Knoten im Netz) so lange zu verändern, bis beispielsweise ein bestimmtes Objekt im Bild immer besser erkannt wird, sondern wir lassen in gewisser Weise offen, nach welchen Mustern und nach welcher Gewichtung gesucht und angepasst wird. Das neuronale Netz bekommt also erstmal keine „Belohnung“ dafür, immer zielsicherer den Hund im Bild zu finden, sondern es versucht lediglich, Gleichartigkeiten zwischen all dem Input, den es bekommt herauszufinden. Und ja – eine solche Gleichartigkeit kann durchaus sein, dass auf bestimmten Bildern Hunde zu sehen sind und auf anderen keine, aber ob dies aus Sicht des Netzes ein sinnvolles Merkmal für das Clustern ist, überlassen wir ihm selbst. Nun drängt sich an dieser Stelle sofort wieder die Frage auf, was die Motivation des neuronalen Netzes ist, solche Muster zu finden – welche kodierte Logik befiehlt also dem Netz, dies zu tun und welche Logik wiederum prüft, dass das Netz sich im eigenen Sinne weiterentwickelt? Und genau das ist ein gutes Beispiel, wo Vieles in der bekannten Literatur im Web versagt, oder einfach nicht genau genug hinsieht: Denn ja, es gibt sehr wohl auch beim unüberwachten Lernen eine Funktion, die hier entscheidend den Impuls für dessen Weiterentwicklung einleitet. Es handelt sich um eine „Objective Function“ – deren Aufgabe ist es, immer besser passende Cluster für die gefundenen Muster zu finden, immer genauer und mit immer weniger Ausreißern. Bewerkstelligen lässt sich das mit mathematischen Funktionen – komplex und äußerst „smart“ ausgelegt, aber in der Praxis sind wir auch hier weit, weit entfernt von echter schöpferischer Leistung. Auch wenn die Ergebnisse teils so sehr überzeugen, dass man gerne menschliche Intelligenz dahinter vermuten möchte.
Gigantisch große Sprachmodelle, LLMs, Generative A.I. und der letzte große Schritt!
Um zu verstehen, wie ein LLM funktioniert, bauen wir nun auf dem auf, was wir bisher gelernt haben. Denn ohne die beschriebene Mustererkennung und das Clustering kann kein LLM (= Large Language Model = Sprachmodell = Generative A.I.) sinnvolle Ergebnisse produzieren.
Sprachmodelle basieren prinzipiell auf dem Ansatz, Textergebnisse Wort für Wort zu generieren (das ist der generative Teil bei Generative A.I.), um möglichst nah und möglichst genau den Inhalt zu treffen, den ein Nutzer als Antwort auf zum Beispiel eine Frage erwarten würde. Alle gängigen, GPT-ähnlichen Chat-Systeme basieren auf dem gleichen Prinzip. Die allgemein gültige Erklärung in Kurzform, dass nach statistischen Prinzipien nach jeder Wortergänzung die Wahrscheinlichkeit des nächsten Wortes berechnet wird, greift zu kurz. Und ganz ehrlich: im Detail ist es deutlich spannender!
Über multidimensionale Vektorräume, die gute, alte Mustererkennung und neuronale Netze.
Wir haben bisher gelernt, dass es beim Unsupervised Learning darum geht, beliebige Muster in Daten, beispielsweise in Bildern zu erkennen. Und so lassen sich diese Prinzipien fast 1:1 auch auf Text anwenden. Die Wissensbasis bei den großen Sprachmodellen ist in diesem Fall keine Sammlung von Bildern, sondern vereinfacht gesagt, all der Text, der im Web zu finden ist. Nach genau demselben Prinzip wurde über Jahre hinweg ein neuronales Netz trainiert (oder wir können nun mit unserem Vorwissen auch sagen, es wurden Gewichte entlang der Kanten verändert), um mit einer fast unendlich groß scheinenden Anzahl an Filtern immer bessere Muster in den Texten zu erkennen. Solche können zum Beispiel die sogenannte semantische Nähe einzelner Wörter zueinander sein. Das Wort „Badezimmer“ wird vermutlich einem Wort „Waschbecken“ näherstehen, als dem Wort „Fahrzeug“. Das Wort „Badezimmer“ aber in Kombination mit dem Wort „Fahrzeug“ kann auch eine Nähe zum Wort „Wohnmobil“ bewirken, et cetera. Diese Kombinationen lassen sich beliebig lange fortsetzen. Neben diesen semantischen Mustern sind aber auch andere Muster relevant, so zum Beispiel Muster, die für den korrekten Satzbau sorgen oder die Länge der Sätze in Relation mit den anderen erkannten Mustern. Wichtig ist zu betonen, dass dies keine expliziten Regeln sind. Es sind Muster, die letzten Endes aus den unendlich groß erscheinenden Textmengen des Web erzeugt wurden. Wenn also beispielsweise im Web Antworten auf beliebige Fragen sehr oft mit Listicles und zwei bis drei Bulletpoints erklärt werden, dann ist auch dies als Muster verankert und kann für einen ähnlichen Textoutput des LLMs sorgen.
Versuchen wir uns für einen Moment vorzustellen, wie unglaublich komplex und weitreichend diese Mustererkennung sein muss, um all das Wissen des Webs semantisch und syntaktisch so zu erfassen, dass es ohne explizite Regeln, ohne Algorithmen auf eine abstrakte Art in Knoten und Kanten eines neuronalen Netzes passt. Kopfzerbrechend faszinierend – ich weiß!
LLMs: Und was hat es nun mit dem Vektorraum auf sich?
Um das Konzept der semantischen Nähe noch etwas weiter auszuführen, hier ein kleiner Einstieg in hochdimensionale Vektorräume. Es klingt kompliziert, aber nur, wenn man versucht sich einen Raum jenseits der uns bekannten drei Dimensionen vorzustellen. Trennen wir uns von diesem Gedanken und lassen für einen Moment zu, dass es neben x, y, z auch a, b, c, d usw. als weitere Dimension geben kann und dies für einen Computer sehr einfach zu repräsentieren und zu berechnen ist. Nun sollte es einfacher sein, das Konzept zu verstehen: Wir speichern nämlich nun in diesen, beliebig vielen Dimensionen die semantische Nähe der Wörter zueinander. In unserem Beispiel von vorhin würde nun in einer beliebigen Dimension „a“ das Wort „Badezimmer“ sehr nahe am Wort „Waschbecken“ zu finden sein. Ist ein Wort „Fahrzeug“ mit im Spiel kann es sein, dass in Dimension „b“ diese Worte eher mit dem Wort „Wohnmobil“ im selben Cluster (anderes Wort für Gruppierung oder bildlich vielleicht am einfachsten als Wolke zu verstehen) liegen. Auch die Syntax, also der Satzbau, ist zum Teil darin gespeichert, wenngleich diese zum größten Teil in den Knoten des neuronalen Netzes verarbeitet wurde. Vektordatenbanken gehen folgerichtig mit dem neuronalen Netz Hand in Hand.

LLMs: Und was ist mit der Belohnung?
Die Literatur ist sich einig: Es gibt bei LLMs kein Belohnungskonzept. Und das ist auch im Grunde korrekt – das Netz, zum Beispiel ChatGPT „lernt“ nicht aktiv weiter oder trainiert seine Knoten und Kanten, um bessere Antworten zu generieren. Es ist bereits „vortrainiert“ und in gewisser Weise statisch. Dennoch hat während der jahrelangen Trainingsphase eine Belohnung maßgeblich zur Performance des Systems beigetragen – denn wie wir bereits gelernt haben, geschieht wirklich nichts im Umfeld der intelligenten, K.I.-basierten Systeme völlig ohne ein Zutun von außen oder gar aus einem schöpferischen Akt. Das Zauberwort an dieser Stelle heißt Reinforcement Learning und ist im Grunde und deutlich vereinfacht dargestellt eine Belohnungsfunktion, die eine „gute“ Entwicklung bei der Gewichtung der Knoten und beim Etablieren von Filtern im neuronalen Netz forciert. So wurde, als Beispiel, über Jahre hinweg und weit vor der Veröffentlichung von ChatGPT mit Hilfe von (menschlichen) Usern und Testern und Antwortmöglichkeiten der Art „War diese Antwort für Sie hilfreich? Ja/Nein“ die Entwicklung maßgeblich beeinflusst. Und nur so konnten anfängliche Chatdialoge wie beispielsweise:
Frage: „Wie funktioniert ein Dieselmotor?“
Antwort: „Wie funktioniert ein Elektromotor?“
sinnvoll aufgelöst werden. Semantisch ähnlich ist die Antwort nämlich in der Tat, syntaktisch korrekt ebenso und mit Sicherheit gibt es viele erkannte Muster in den Daten, die genau so eine Antwort unterstützen würden. Nur macht sie natürlich menschlich betrachtet keinen Sinn. Das Reinforcment Learning sorgt damit für zusätzliche Gewichtungen im Netz, um Antworten zu optimieren.
Wie generiert das LLM die Antwort?
Mit diesen Erklärungen im Hinterkopf sollte es uns nun einfacher fallen, die Wort-für-Wort-Textgenerierung von LLMs (und damit Generative A.I.) zu verstehen. Wir gehen nun ein praktisches Beispiel durch:
- Ein User stellt eine beliebige Frage an das LLM seiner Wahl, bspw. den Klassiker ChatGPT. Dazu formuliert er einen Text und sendet diesen ab.
- Im ersten Schritt wird das Sprachmodell den erhaltenen Text zerlegen und versuchen, die semantische Nähe zu existierenden Inhalten im n-Dimensionalen Vektorraum zu finden. Dazu werden die angefragten Worte mit den Verfahren der hochdimensionalen Vektordarstellung und der dort anzutreffenden Inhalte geclustert. Wie wir wissen, spielt dabei jedes erdenkliche Muster eine wichtige Rolle. Die Wörter zueinander, der Satzbau, die Satzzeichen, der Kontext – einfach alles.
- Ist im hochdimensionalen Vektorraum die semantische Nähe gefunden, beginnt der erste Schritt der Antwortformulierung.
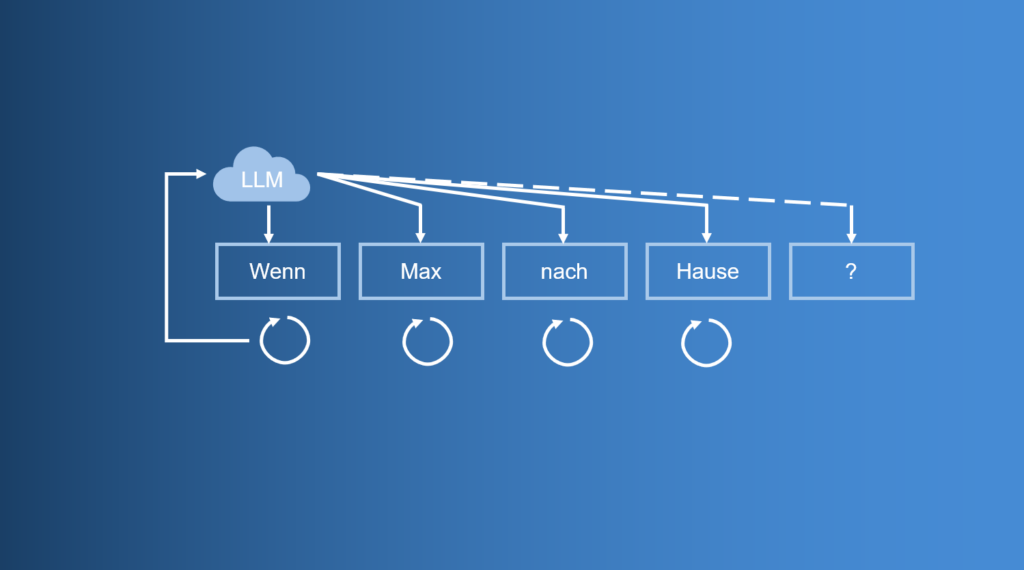
- Für das erste Wort (und auch die folgenden) ist die Mustererkennung im neuronalen Netz entscheidend. Es gibt nämlich Layer (Knoten und Kanten) die Muster erkennen, die auf eine Frage hindeuten und auch „wissen“, wie und mit welchem Wort eine Antwort am zielführendsten beginnt. Dieses Wort wird generiert.
- Das Verfahren sieht nun vor, den Frage-Input-Text und damit den Kontext, zeitgleich mit dem bereits generierten ersten Wort der Antwort erneut in das neuronale Netz zu schicken, um das zweite Wort zu generieren. Und auch beim zweiten Wort wird erneut auf Muster geachtet, die nun mit dem zuvor generierten Wort getroffen werden. Ein nächstes Wort, ein drittes Wort wird generiert, welches anhand der Muster für das statistisch sinnvollste erachtet wird.
- Dieser Prozess wird so oft fortgeführt, bis ein weiterer Knoten im Netz mit der entsprechenden Gewichtung (abgeleitet aus den Mustern im Web – haben wir ja nun gelernt) die „Entscheidung“ trifft, dass der Satz beendet ist, oder genug Text generiert wurde, um eine ausreichend sinnvolle Antwort zu bilden.
Lessons learned: Die Magie steckt zwischen den Zeilen, nicht im schöpferischen „Neuen“
Zum jetzigen Zeitpunkt müsste es für die meisten Leser mindestens ein bis zwei Stellen geben, an denen man neidvoll anerkennen muss, dass dies wirklich Rocket Science ist. Allein der Versuch dieses „Monstrum“ an Mustererkennung zu umreißen, macht sprachlos. Und wenn es nicht das sein sollte, dann die Tatsache, dass es niemanden (und damit meine ich keinen Menschen) auf der Welt gibt, der diese Muster vorab definiert oder festgelegt hat. Nein, das Netz hat sich im Rahmen seiner Freiheitsgrade selbstständig geformt – der eigentliche Inhalt darin bleibt uns verschlossen. Wir kennen tatsächlich nicht, wie diese Muster aussehen. Wissen nicht, was das Netz dazu gebracht hat die Antworten exakt so zu formulieren, wie es dies getan hat. Wissen nicht genau, wo gespeichert ist, dass Antworten mit drei Unterpunkten scheinbar zielführender sind als andere Formen der Strukturierung. Und sind auch darüber erstaunt, dass ein Sprachmodell, welches auf Basis des Web trainiert wurde, tatsächlich in der Lage ist andere Sprachen zu verstehen und diese auch zielsicher zu generieren. Ziehen wir den Vergleich zum Menschen: Sein Lernprozess und die abstrakte Repräsentation von Wissen in einer neuronalen Struktur ist ihm nicht fremd – schließlich war dies auch die Blaupause für die meisten Durchbrüche im Bereich der A.I.. Auch hier wissen wir nicht, welche Neuronen zu welchem Zeitpunkt bei der Beurteilung und Entscheidungsfindung beteiligt sind oder zu welchem Zeitpunkt sich die Gewichtung der Verbindungen zwischen den Neuronen verändert hat und ein bestimmtes Wissen darin repräsentiert liegt. Also ist ein neuronales Netz also doch ein Akt der Schöpfung? Nicht wirklich, denn solange wir auch bei uns Menschen noch immer nicht verstehen, was Schöpfung eigentlich bedeutet, was Bewußtsein ist, was eine wirklich freie Entscheidung ausmacht, solange lässt sich dieses Verhalten kaum in ein neuronales Netz transferieren. Auch wenn die Mechanismen vergleichbar sind, so sollten wir nicht das vergessen, was wir bereits beim Supervised Learning gelernt hatten: Die Filtermechanismen sind prinzipiell vordefiniert. Und so komplex und schwer nachvollziehbar manche Entscheidungswege im LLM sein mögen, so faszinierend oder gar erschreckend manche Lernwege (beispielsweise eine Fremdsprache zu erlernen) auf uns wirken, so klar ist jedoch auch, dass keine gänzlich neuen, von gelernten Mustern abweichende Ergebnisse zu erwarten sind. Hier spielt auch sicher wieder der nichtexistierende „Zufall“ in der IT eine Rolle, dessen menschliches Pendant sehr oft Anstoß für neue Denkrichtungen ist. Dies ist wohl nur in einer sogenannten „Starken A.I.“ zu erwarten – und von dieser sind wir nach heutigem Stand und trotz der Durchbrüche der letzten Jahre, noch ein ganzes Stück entfernt.







