Classification in automotive data science – everything you need to know
Data, data, data - nothing works without them, but as is so often the case, they must first be used to determine what (whatever) profit growth might look like. Interpretability is an essential ingredient, and in industrial machine learning, where a wide variety of models want to be trained with data, this is especially true. In what form is the collected data available, and what is the next step? These are the questions addressed in the second part of our series of articles on industrial machine learning with today's topic of classification. The first article about clustering can be found here ► click the link and say hello to Captain k-means from us!
At this point, we now continue with the classification explanation, for which we sought input from our Team Lead Data Science & A.I., Dr. Daniel Isemann, among others - enjoy!
- What is classification, and please not just gray theory, but examples!
- Classification - Functional and efficient, but also a bit fun
- How do we situate classification in the field of machine learning?
- Classification and its methods: The main algorithms
- Classification and labels: How many people do I have to put on it?
- Classification and the gut feeling - Partners in Crime?
- Farewell to classification (...but only for today!)

Marc
Marketing Professional
14.11.22
Ca. 17 min
What is classification, and please not just gray theory, but examples!
Let’s first get a purely linguistic detail out of the way: “classification” can also be called “classification”, and you may say both “classify” and, somewhat less familiar, “classify”. Interestingly, “he was declassified”, common from sports, is somewhat better known, although linguistically it is actually mostly used inaccurately. Back to the field of machine learning, you will often encounter the English “classification” due to the high number of anglicisms. However, they all describe the same thing, namely a methodology for dividing (data) objects into classes.
In industrial machine learning – in this article not exclusively, but preferably related to the automotive sector – we are talking about lots of data. Petabytes of data collected on the roads, via test vehicles, video streams, massive amounts of images and other sources, accumulating gigantic mountains of data in a short period of time. To make the abstract – which plays a major role here – a little clearer, we will use an example: In a vehicle with autonomous driving assistance systems, there is an electric motor, but it only switches on when a camera sends a signal to the relevant control unit. This is what the camera, or the A.I. behind it, does when it detects a red light – the electric motor turns on, the gasoline engine turns off, and the vehicle glides electrically to a stop or continues on, reducing gasoline consumption. So the camera must first automatically detect the traffic light, and then the position of the traffic light, which is composed of color and position. So how does the A.I. know what is “right” and what is “wrong”? How does she make this decision, which is actually quite simple for us humans? It was trained to her, by means of a model in which it is determined what is green (drive, do not turn on the electric motor) and red (switch to “sailing mode” and glide via electric motor to the traffic light). This model was fed with data, with images, videos and signals of red and green traffic lights, at standstill, in motion, from various angles, possibly taking into account whether there are objects between the traffic light and the vehicle, other road users for example. This data was categorized and thus evaluated and processed into meaningful signals by means of classification.

Classification – Functional and efficient, but also a bit fun
In order for this collected data to become usable and not just an indeterminate signal in a multidimensional space, it needs a label, namely “green” or “red” in our example. This can be done in different ways: Of course manually, by a test person clearly defining whether an e.g. image just shows a red or green traffic light. Several people may agree on exactly when a traffic light is red or green – or yellow, as the case may be. A popular form of manual labeling is represented by specific online forums, where many users can assign a lot of data in a comparatively short time. In the case of very large data volumes, however, automation via algorithms is an option – due to the lack of labels, classification cannot yet be effective here, but clustering could be a solution, whether as a final procedure, with the results of which a model can already be sufficiently trained, or as a preliminary stage to classification.
So now that we have the labeled data, we can train the model, and it can find and categorize, i.e., classify, newly added data that was not previously unknown. Another popular example is the email inbox spam filter we all know: is the incoming email spam or not? Here are almost amusing examples of the logic inherent in this specific form of Data Science: We send 100 emails, one of which is spam. The spam filter does not recognize this spam mail, but delivers all mails without any problems – so it is still 99 percent accurate at first. To mitigate this, correspondingly large amounts of data are required, which in turn makes manual labeling absurd and subsequently requires reliable algorithms that can develop a good model and also upgrade it later.
It also goes without saying that the data must be reliable and accurate for a model to work reliably. A faulty labeling would consequently also lead to a faulty model. At the latest in frequent output of “false negatives” or “false positives” (i.e. not shutting down the engine despite a red light, or constant spam in the mailbox), errors in the model would come to light. However, a good classification and a subsequently strong model can well prevent this undesirable case.
How do we situate classification in the field of machine learning?
When we speak of “machine learning”, we usually refer to the definition of Arthur L. Samuels: “Programming computers to learn from experience should eventually eliminate the need for much of this detailed programming effort.” So it’s all about learning – Samuels, for example, programmed a checkers-playing application as early as 1959 that beat Connecticut’s national checkers champion, even though Samuels himself wasn’t very good at it (read about it in the book Computers and Thought by Edward Feigenbaum and Julian Feldman). The popular saying that a program is only as good as its programmer can be easily disproved thanks to machine learning. Overall, this means that machine learning refers to simplifying learning processes. Admittedly, this has evolved to the present day and scaled up to industrial solutions and is used in a variety of scenarios in everyday life, whether in the financial sector, in medicine (here we recommend our really exciting Article in which we explain how data science experience gained in the automotive sector is conquering medicine) or in the automotive industry. Often, when industrial machine learning is mentioned there, it is usually about neural networks or deep learning.
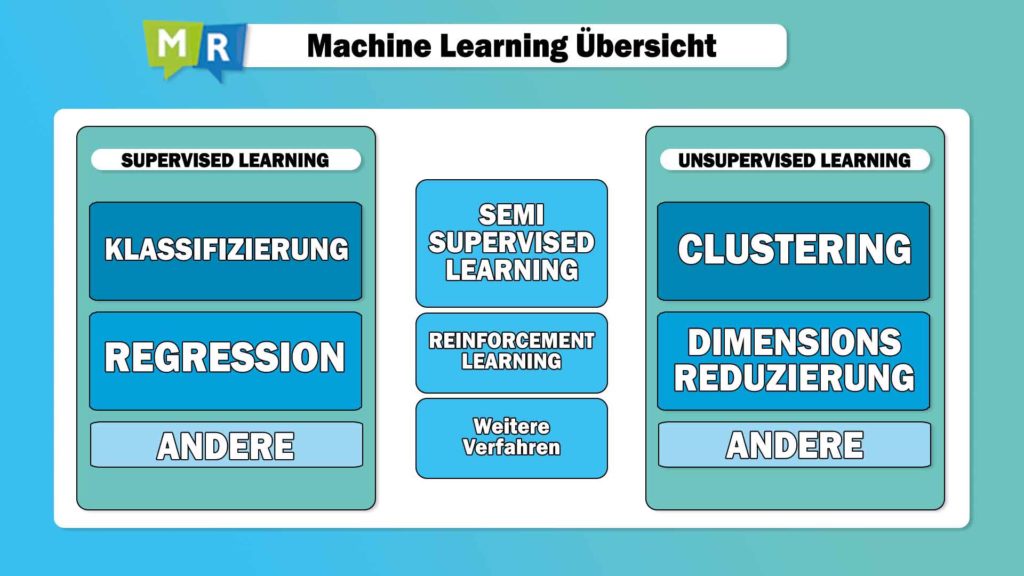
Within this domain, we mainly distinguish between supervised and unsupervised learning methods. In the unsupervised area, we can make another division into either clustering methods, or dimension reduction methods – we’ll explain those to you in a separate article, otherwise it’s getting a bit too detailed for today.
In contrast, there is the area of supervised learning, of which classification is certainly the most prominent representative. Honorable mentions go to regression analysis, which is not intended to predict classes but numerical values – a completely different application scenario, in other words, from classification, which predicts classes, such as “A”, “B”, or “C” (or a bucket where everything from “0-1” belongs to “A”, everything from “1-20” belongs to “B”, etc.). So the classification is about categories, about labels, with which the desired model is trained, which can therefore finally recognize from the sent camera image that our control unit for the electric motor is to be activated.
Classification and its methods: The main algorithms
Within classification, we look at another set of methods that are suitable for classifying data, and we will talk about them in more detail in a moment, but first in general terms: Neural networks form a large part of the known applications (which could theoretically be applied to all other methods as well, especially in reinforcement learning), and similarly well-known and frequently used are the kernel-based methods (support vector machines).
Regarding “reinforcement learning”, which has not been mentioned before, it should be summarized at this point that, similar to other methods from “semi-supervised learning”, this is a learning paradigm that is neither supervised nor unsupervised – we will also discuss this further in a forthcoming article.
Also of high relevance in classification are tree-based methods such as the decision trees, which have been known for a long time – although these are now used more in ensembles, whole tree fields or forest methods (the best-known representative is certainly “Random Forest”). If you don’t have a lot of data but need fast results, you can also use “Extreme Gradient Boosting”, more commonly referred to as “XG Boost”.
Meanwhile, the question of which algorithm is the big winner in classification remains difficult to answer. Often it is the one with which the corresponding service provider has the most experience, and even more often the data is simply processed with several algorithms. The comparison of results shows which algorithm is the most suitable. This is used accordingly to train the final model. Ultimately, it is often also a question of budget – those who have a lot of data and can afford to train a model extensively can work with Deep Learning, which also likes to present itself here as the strongest participant in the field of classification algorithms. However, if only a small amount of data is available, Deep Learning is no better than other algorithms, and more than once XG Boost proved to be the winner at the end of the day.

It is also clear that the more data available, the more accurate a result will generally be, although this is also at the expense of interpretability, and experience has shown that most algorithms ultimately produce similar results – with the exception of the muscleman “Deep Learning”, which can be used to determine the most accurate results, especially over the long term.
Classification and labels: How many people do I have to put on it?
Not only does this data need to be collected, but, as we talked about earlier, it also needs to be labeled, because supervised learning is dependent on labels. There are definitely different ways to get these labels, although in many people’s minds there is still the idea that you need a large number of people who put a lot of effort into labeling data manually – which takes time and resources and generates costs. In reality, however, labels can sometimes be generated by processes that are taking place anyway, such as the evaluation of error tickets by subject matter experts as part of problem management, or by user feedback and similar sources. From this, labels can often be derived directly or indirectly, which can be used for the actual classification task.
However, this does not change the fact that data should also be interpretable versus model goodness of fit. For a better understanding: If we use a decision tree, we can see at each branch why the corresponding decision was made, i.e. we can understand the decisive decision criterion. Why a particular data point is categorized into a specific class is more or less clear.
At the other end of the spectrum, for example, is a process like Deep Learning. Here hundreds, thousands or more “data nodes” exist in a highly complex model whose interpretability is no longer given. In this case, it is almost acceptable that the decision is made on the basis of the given training data, without seeing in detail how the decision was made.
Classification and the gut feeling – Partners in Crime?
Not necessarily technically robust, but nevertheless a nice example is that of an auto mechanic: This person can use certain rules to determine whether an engine is too noisy, which indicates specific damage. If this is checked, the error can be found and corrected. This is simple and understandable. However, there are also damages that sound similar but have other causes. Finding them may also require new patterns of recognition. An experienced master mechanic, on the other hand, “knows” the engine type very well and can make a competent decision based on his “gut feeling”. This is not a transparent process and is rather difficult to communicate and track, thus not concretely repeatable in the same form. Nevertheless, this example is quite obvious, since especially neural networks are supposed to represent a certain emulation of human decision making, and thus intuition also plays a role in the classification – explained in a simplified way.
Having to decide between interpretability and model quality is not always easy; however, as so often, there are quite reliable middle paths, of which Random Forest is particularly worth mentioning here: Here, explicability is no longer possible at each individual branch in the decision-making process, but insight into the overarching decision criteria does exist.
Farewell to classification (…but only for today!)
Let’s start the conclusion of the paper with a quote attributed to Daniel Keys Moran, a programmer and author: “You can have data without information, but you can’t have information without data”. In the context of industrial machine learning, it is usually the third variant, namely: a lot of data with a lot of information that needs to be sorted, i.e.: classified, in order to enable an evaluation in the first place and thus the operation of many functions and products. Especially with extremely high data volumes, efficient use of the collected information is hardly possible without Big Data pipelines, machine learning and clustering or classification. We are of course happy to advise if too much data raises questions or otherwise needs to be evaluated efficiently. And recommend you check out our blog even further, whether it’s on Data Science or our other exciting portfolio topics.







